Hello, we are researching the cms-kit module as an option to store our application's customer facing knowledge base. The knowledge base contains the guides how to use the main application. One thing I would like to clarify is how would we implement the page localisation. We need the same KB page in different languages. Does the the cms-kit support this use case by default? If not how should we create the pages and support this use case?
Hi
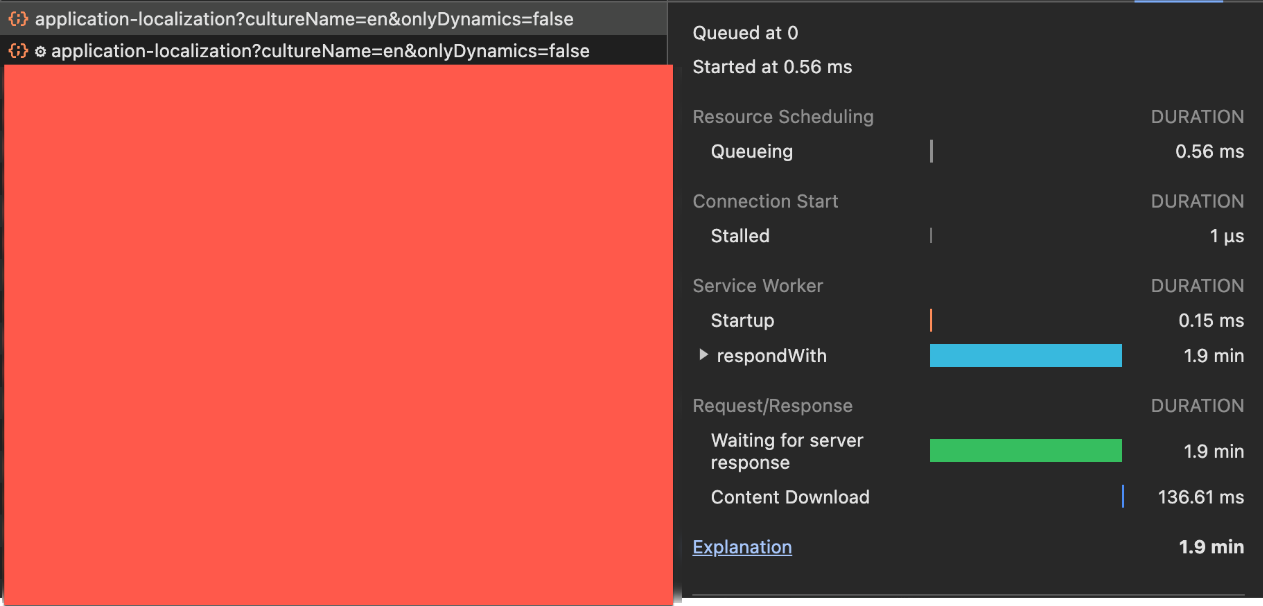
We are experiencing an issue where exceptions are not being properly logged with their full details to Application Insights.
Problem: When an error occurs, we only see a generic error message in the logs, not the actual exception details or stack trace.
Example from Application Insights:
MessageTemplate: ---------- RemoteServiceErrorInfo ----------
{
"code": null,
"message": "Sisäinen virhe tapahtui pyynnön käsittelyssä.",
"details": null,
"data": null,
"validationErrors": null
}
RequestPath: /api/abp/application-localization
ActionName: Volo.Abp.AspNetCore.Mvc.ApplicationConfigurations.AbpApplicationLocalizationController.GetAsync (Volo.Abp.AspNetCore.Mvc)
Expected behavior: We want to hide exception details from the client (for security), but still log the full exception with stack trace to Application Insights for debugging purposes.
Questions:
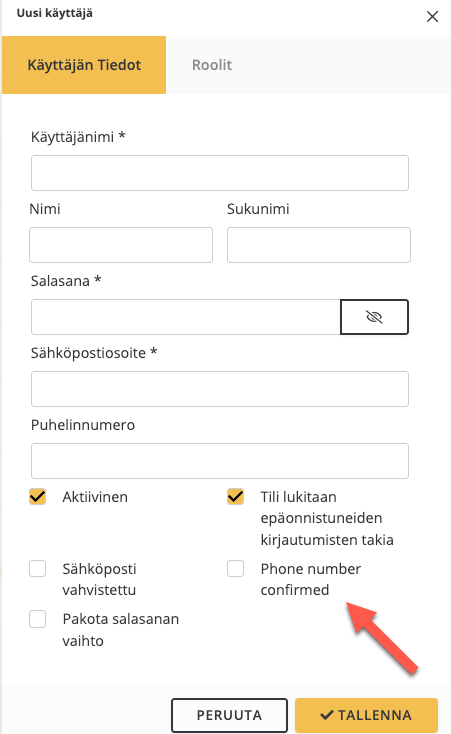
IExceptionFilter or override IExceptionToErrorInfoConverter?Where is this key defined. I did not find it from anywhere. The field is for "phone number confirmed" and language is finnish (fi-FI)
Hi,
We have an ABP Framework applications running on Azure App Services. E-mail is sent via SendGrid SMTP.
Issue After the app has been running for a while, outgoing e-mails stop being sent. Nothing appears in our SendGrid activity log, so the messages never reach SendGrid. Restarting our two web apps (API host and Auth server) immediately restores e-mail delivery, but the problem reappears after some days of uptime.
Could you suggest what might cause this and what to check next?
We have a very serious issue in our production environment where the above mentioned queries have started to take a lot of time. Somethimes they work fast but quite often they take several minutes. Other features of our application work smoothly so overall resource constrictions have been ruled out. Now we need help from you on how to dissect this problem since this is pure Abp code.
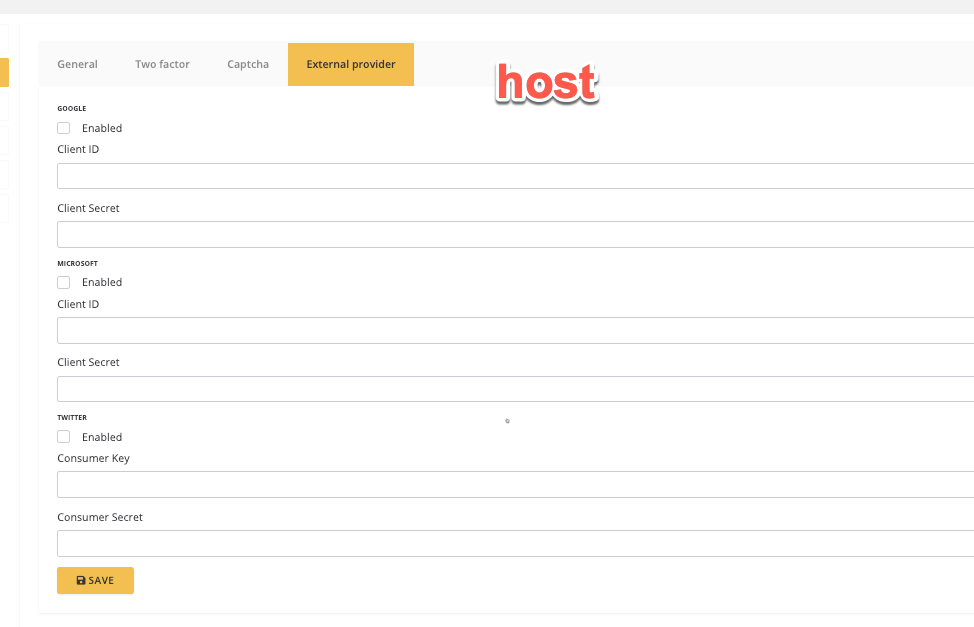
How to configure different external login providers for different tenants? Based on this answer https://github.com/abpframework/abp/discussions/19743, I suppose this is possible somehow but there is no place in the tenant side to configure this. Please provide instructions, how can we configure this.

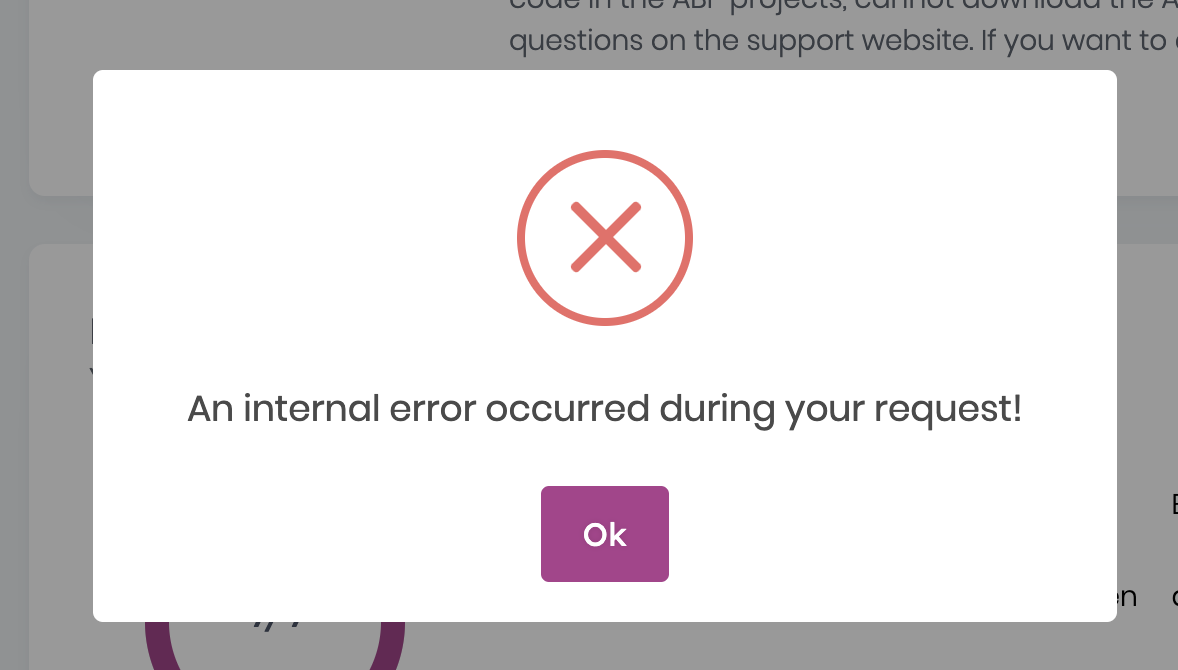
Hello,
When removing seat from a developer I'm unable to do so. Tried with multiple browsers and incognito without no success. Please assist how to release license to be used for another user.
Best Regards LW
Hi, we have used and trusted Abp Framework for several years now. You provide an awesome framework which makes our lives so much easier. Thank you for this! However our trust is lost on the abp nuget server to function at all times. This is a critical service for us who deploy multiple times a day to production. If the nuget server is down, our production pipeline will halt. We need a way to mitigate this problem! My hope, as I have previously proposed, would be to be able to download all the nuget packages programmatically from the server. I first asked about this in here: https://support.abp.io/QA/Questions/5549/A-way-to-list-all-nuget-packages-from-Abp-nuget-server. I provided this solution because we use Azure Artifacts, which does not support custom nuget feeds. This way we could download the packages and push them to an Azure Artifacts feed separately.
One of our tenant wants to have roles with a different language. We tried to do this by changing the role names in that tenant's database, leaving the normalised name intact. We need to leave the normalised name intact so we can still seed role permissions normally. This did not work, however, because permission grants reference the role table with the role name, not the normalised name or id. Why is that, and can this be changed, in order to support the role name localisation?
Is there a way to list and download all the nuget packages from the nuget server (https://nuget.abp.io/ID/v3/index.json) programmatically? I would like the cache the packages since there has been incidents where some of the package sources has been down.




























































