


























































5 Things You Should Keep in Mind When Deploying to a Clustered Environment
Let’s be honest — moving from a single server to a cluster sounds simple on paper.
You just add a few more machines, right?
In practice, it’s the moment when small architectural mistakes start to grow legs.
Below are a few things that experienced engineers usually double-check before pressing that “Deploy” button.
1️⃣ Managing State the Right Way
Each request in a cluster might hit a different machine.
If your application keeps user sessions or cache in memory, that data probably won’t exist on the next node.
That’s why many teams decide to push state out of the app itself.
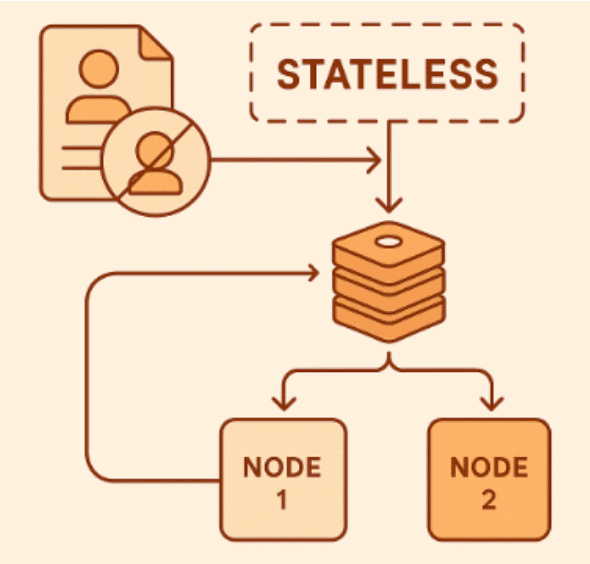
A few real-world tips:
- Keep sessions in Redis or something similar instead of local memory.
- Design endpoints so they don’t rely on earlier requests.
- Don’t assume the same server will handle two requests in a row — it rarely does.
2️⃣ Shared Files and Where to Put Them
Uploading files to local disk? That’s going to hurt in a cluster.
Other nodes can’t reach those files, and you’ll spend hours wondering why images disappear.
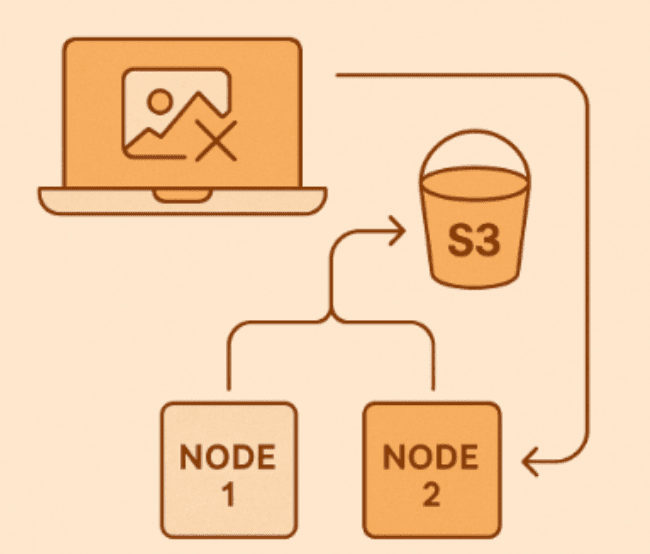
Better habits:
- Push uploads to S3, Azure Blob, or Google Cloud Storage.
- Send logs to a shared location instead of writing to local files.
- Keep environment configs in a central place so each node starts with the same settings.
3️⃣ Database Connections Aren’t Free
Every node opens its own database connections.
Ten nodes with twenty connections each — that’s already two hundred open sessions.
The database might not love that.
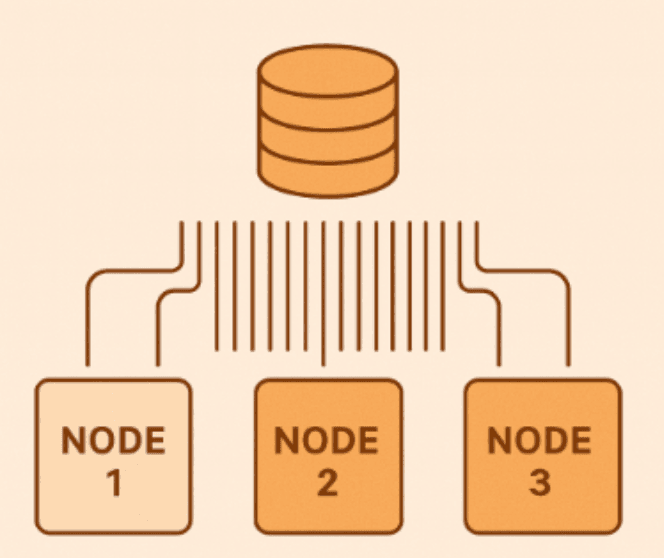
What helps:
- Put a cap on your connection pools.
- Avoid keeping transactions open for too long.
- Tune indexes and queries before scaling horizontally.
4️⃣ Logging and Observability Matter More Than You Think
When something breaks in a distributed system, it’s never obvious which server was responsible.
That’s why observability isn’t optional anymore.
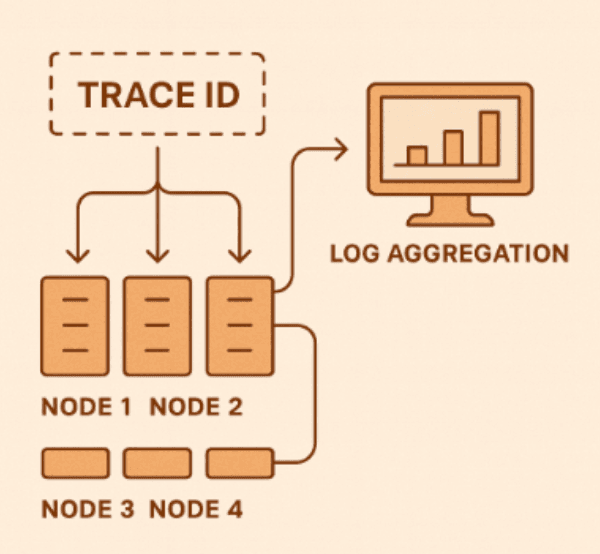
Consider this:
- Stream logs to ELK, Datadog, or Grafana Loki.
- Add a trace ID to every incoming request and propagate it across services.
- Watch key metrics with Prometheus and visualize them in Grafana dashboards.
5️⃣ Background Jobs and Message Queues
If more than one node runs the same job, you might process the same data twice — or delete something by mistake.
You don’t want that kind of excitement in production.
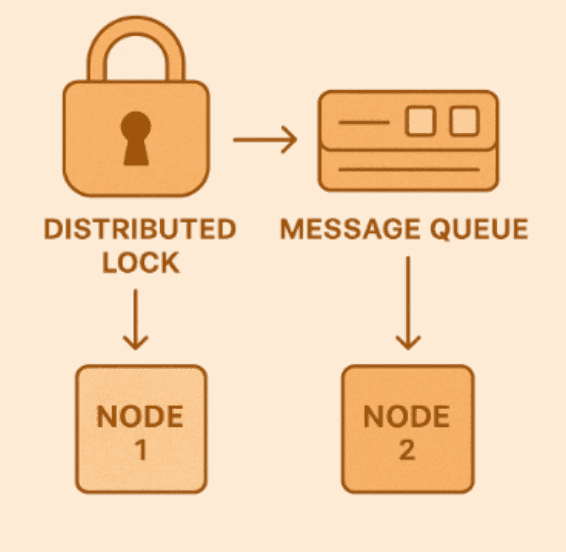
A few precautions:
- Use a distributed lock or leader election system.
- Make jobs idempotent, so running them twice doesn’t break data.
- Centralize queue consumers or use a proper task scheduler.
Wrapping Up
Deploying to a cluster isn’t only about scaling up — it’s about staying stable when you do.
Systems that handle state, logging, and background work correctly tend to age gracefully.
Everything else eventually learns the hard way.
A cluster doesn’t fix design flaws — it magnifies them.


Comments
Halil İbrahim Kalkan 16 weeks ago
Thanks for sharing. Also see https://abp.io/docs/latest/deployment/clustered-environment
Frank Scott 5 weeks ago
Great tips! Managing state, shared files, and database connections are often overlooked until they become real headaches in a clustered environment. Observability is definitely key without proper logging, debugging distributed systems can turn into a nightmare. On a lighter note, while scaling apps and infrastructure, it’s also nice to have some downtime and relax with mobile gaming. Platforms like gamehub.onl make it easy to discover new games and unwind after a long day of engineering challenges.