





















































Microservice Startup Template: Database Migrations
Running SQL-Server infrastructural service is required since default connection strings for microservices use SQL-Server running on container.
There are two ways to migrate databases and seed data for microservices. Either one of them or both of them can be used as long as data seeders are synced.
Auto Migration (On-the-fly Migration)
RabbitMq infrastructural service is required for auto migration along with SQL-Server.
The aspect of auto migration is, that each microservice migrates its own database and seeds its own data. To achieve this, each microservice checks pending migration and handles it on its own. To achieve that, microservices acquire a distributed lock and apply the database migration to prevent multiple replicas to try migrating the already migrated database.
Microservices have a DbMigrations folder that contains DatabaseMigrationChecker and DatabaseMigrationEventHandler specific to that microservice. Since this behavior is shared across all the microservices, it has been defined as PendingEfCoreMigrationsChecker.
Each microservice extends the PendingEfCoreMigrationsChecker and runs the DatabaseMigrationChecker at OnPostApplicationInitialization method.
Each migration tries to lock and apply database migrations under PendingEfCoreMigrationsChecker base class:
public virtual async Task CheckAndApplyDatabaseMigrationsAsync()
{
await TryAsync(LockAndApplyDatabaseMigrationsAsync);
}
The retry mechanism is implemented under the TryAsync method if the database is not reachable or not ready yet. By default, it has 3 retry counts and this can be modified under the PendingMigrationsCheckerBase. The distributed lock is used to prevent multiple concurrent applications (replicas) are trying to migrate the same database.
Under the LockAndApplyDatabaseMigrationsAsync method, when the distributed lock is acquired; the database is migrated based on pending migrations:
public async Task LockAndApplyDatabaseMigrationsAsync()
{
await using (var handle = await DistributedLock.TryAcquireAsync("Migration_" + DatabaseName))
{
if (handle is null)
{
return;
}
using (CurrentTenant.Change(null))
{
// Create database tables if needed
using (var uow = UnitOfWorkManager.Begin(requiresNew: true, isTransactional: false))
{
var dbContext = await ServiceProvider
.GetRequiredService<IDbContextProvider<TDbContext>>()
.GetDbContextAsync();
var pendingMigrations = await dbContext
.Database
.GetPendingMigrationsAsync();
if (pendingMigrations.Any())
{
await dbContext.Database.MigrateAsync();
}
await uow.CompleteAsync();
}
}
}
}
On-the-fly migration is achieved by using the distributed event system by handling the ApplyDatabaseMigrationsEto distributed event in the DatabaseMigrationEventHandler.
public async Task HandleEventAsync(ApplyDatabaseMigrationsEto eventData)
{
if (eventData.DatabaseName != DatabaseName)
{
return;
}
try
{
var schemaMigrated = await MigrateDatabaseSchemaAsync(eventData.TenantId);
if (eventData.TenantId == null && schemaMigrated)
{
await QueueTenantMigrationsAsync();
}
}
catch (Exception ex)
{
await HandleErrorOnApplyDatabaseMigrationAsync(eventData, ex);
}
}
After the host database migrations by queueing a new ApplyDatabaseMigrationsEto event passing TenantId argument.
protected virtual async Task QueueTenantMigrationsAsync()
{
var tenants = await TenantRepository.GetListWithSeparateConnectionStringAsync();
foreach (var tenant in tenants)
{
await DistributedEventBus.PublishAsync(
new ApplyDatabaseMigrationsEto
{
DatabaseName = DatabaseName,
TenantId = tenant.Id
}
);
}
}
This is handled under MigrateDatabaseSchemaAsync(Guid? tenantId) method of DatabaseMigrationEventHandlerBase.
protected virtual async Task<bool> MigrateDatabaseSchemaAsync(Guid? tenantId)
{
var result = false;
using (CurrentTenant.Change(tenantId))
{
...
}
return result;
}
With this feature; the newly created tenant with a specified connection string will have its new database automatically created with all the tables and the initial seed data if available. Tenant management UI also has a manual trigger for database creation & migration in case any problem occurs with automatic migration.
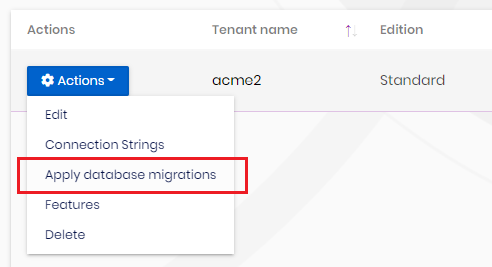
If you don't want to use Auto Migration for any microservice, delete the
OnPostApplicationInitializationmethod of the HttpApiHost module and microservice-specific DatabaseMigrationChecker file along with related DataSeeder.
Database Migrator
If you want to use only Auto Migration (On-the-fly-Migration), it is safe to delete this project completely.
DbMigrator is a console application and used for database migrations and seeding data. It is located under the shared folder in the microservice template solution. DbMigratorModule depends on SharedHostingModule to use mapped database configurations. Since it will be migrating the databases of microservices; it also depends on each microservice's EntityFrameworkCoreModule and ApplicationContractsModule modules.
DbMigratorService first migrates the host then the tenants.
public async Task MigrateAsync(CancellationToken cancellationToken)
{
await MigrateHostAsync(cancellationToken);
await MigrateTenantsAsync(cancellationToken);
_logger.LogInformation("Migration completed!");
}
MigrateHostAsync method migrates all the databases.
private async Task MigrateAllDatabasesAsync(Guid? tenantId, CancellationToken cancellationToken)
{
...
if (tenantId == null)
{
/* SaaS schema should only be available in the host side */
await MigrateDatabaseAsync<SaasServiceDbContext>(cancellationToken);
}
await MigrateDatabaseAsync<AdministrationServiceDbContext>(cancellationToken);
await MigrateDatabaseAsync<IdentityServiceDbContext>(cancellationToken);
await MigrateDatabaseAsync<ProductServiceDbContext>(cancellationToken);
await uow.CompleteAsync(cancellationToken);
...
}
MigrateTenantsAsync method migrates each tenant based on their connection string
private async Task MigrateTenantsAsync(CancellationToken cancellationToken)
{
...
var tenants = await _tenantRepository.GetListAsync(includeDetails: true, cancellationToken: cancellationToken);
var migratedDatabaseSchemas = new HashSet<string>();
foreach (var tenant in tenants)
{
using (_currentTenant.Change(tenant.Id))
{
// Database schema migration
var connectionString = tenant.FindDefaultConnectionString();
if (!connectionString.IsNullOrWhiteSpace() && //tenant has a separate database
!migratedDatabaseSchemas.Contains(connectionString)) //the database was not migrated yet
{
_logger.LogInformation($"Migrating tenant database: {tenant.Name} ({tenant.Id})");
await MigrateAllDatabasesAsync(tenant.Id, cancellationToken);
migratedDatabaseSchemas.AddIfNotContains(connectionString);
}
//Seed data
...
}
}
}
If you decide to use both DbMigrator and Auto Migration approaches, you need to keep duplicate dataseeder files; one under your microservice DbMigrations folder for auto migration and the other under the shared DbMigrator project. You need to keep both of your data seeder files synchronized.
IdentityService Data Seeding
IdentityService uses three different mapped database configurations; IdentityService, AdministrationService and SaasService which are located under appsettings.json file.
IdentityService seeding is required for AuthServer since it seeds the admin user/password (identity data) and initial OpenIddict data (applications, scopes).
OpenIddict Data Seeding
Both Auto Migration Data Seeding and DbMigrator Data Seeding use OpenIddictDataSeeder. The seeder uses OpenIddict section in appsettings.json file to seed client and resource cors and redirectUri data.
"OpenIddict": {
"Applications": {
"MyProjectName_Web": {
"RootUrl": "https://localhost:44321/"
},
"MyProjectName_Blazor": {
"RootUrl": "https://localhost:44307/"
},
"MyProjectName_BlazorServer": {
"RootUrl": "https://localhost:44314/"
},
"MyProjectName_PublicWeb": {
"RootUrl": "https://localhost:44335/"
},
"MyProjectName_Angular": {
"RootUrl": "http://localhost:4200"
},
"WebGateway": {
"RootUrl": "https://localhost:44325"
},
"PublicWebGateway": {
"RootUrl": "https://localhost:44353"
}
},
"Resources": {
"AccountService": {
"RootUrl": "https://localhost:44322"
},
"IdentityService": {
"RootUrl": "https://localhost:44388"
},
"AdministrationService": {
"RootUrl": "https://localhost:44367"
},
"SaasService": {
"RootUrl": "https://localhost:44381"
},
"ProductService": {
"RootUrl": "https://localhost:44361"
}
}
}
Creating API Scopes
Each scope is defined individually.
private async Task CreateApiScopesAsync()
{
await CreateScopesAsync("AccountService");
await CreateScopesAsync("IdentityService");
await CreateScopesAsync("AdministrationService");
await CreateScopesAsync("SaasService");
await CreateScopesAsync("ProductService");
}
Creating Web Gateway Swagger Client
Web Gateway Swagger client is the only swagger client used for all swagger authorization in between microservices and gateways.
private async Task CreateWebGatewaySwaggerClientsAsync()
{
await CreateSwaggerClientAsync("WebGateway", new[] { "AccountService", "IdentityService", "AdministrationService", "SaasService", "ProductService" });
}
private async Task CreateSwaggerClientAsync(string name, string[] scopes = null)
{
var commonScopes = new List<string>
{
OpenIddictConstants.Permissions.Scopes.Address,
OpenIddictConstants.Permissions.Scopes.Email,
OpenIddictConstants.Permissions.Scopes.Phone,
OpenIddictConstants.Permissions.Scopes.Profile,
OpenIddictConstants.Permissions.Scopes.Roles
};
// Swagger Client
var swaggerClientId = $"{name}_Swagger";
if (!swaggerClientId.IsNullOrWhiteSpace())
{
var webGatewaySwaggerRootUrl = _configuration[$"OpenIddict:Applications:{name}:RootUrl"].TrimEnd('/');
var publicWebGatewayRootUrl = _configuration[$"OpenIddict:Applications:PublicWebGateway:RootUrl"].TrimEnd('/');
var accountServiceRootUrl = _configuration[$"OpenIddict:Resources:AccountService:RootUrl"].TrimEnd('/');
var identityServiceRootUrl = _configuration[$"OpenIddict:Resources:IdentityService:RootUrl"].TrimEnd('/');
var administrationServiceRootUrl = _configuration[$"OpenIddict:Resources:AdministrationService:RootUrl"].TrimEnd('/');
var saasServiceRootUrl = _configuration[$"OpenIddict:Resources:SaasService:RootUrl"].TrimEnd('/');
var productServiceRootUrl = _configuration[$"OpenIddict:Resources:ProductService:RootUrl"].TrimEnd('/');
await CreateClientAsync(
name: swaggerClientId,
type: OpenIddictConstants.ClientTypes.Public,
consentType: OpenIddictConstants.ConsentTypes.Implicit,
displayName: "Swagger Client",
secret: null,
grantTypes: new List<string>
{
OpenIddictConstants.GrantTypes.AuthorizationCode,
},
scopes: commonScopes.Union(scopes).ToList(),
redirectUris: new List<string> {
$"{webGatewaySwaggerRootUrl}/swagger/oauth2-redirect.html", // WebGateway redirect uri
$"{publicWebGatewayRootUrl}/swagger/oauth2-redirect.html", // PublicWebGateway redirect uri
$"{accountServiceRootUrl}/swagger/oauth2-redirect.html", // AccountService redirect uri
$"{identityServiceRootUrl}/swagger/oauth2-redirect.html", // IdentityService redirect uri
$"{administrationServiceRootUrl}/swagger/oauth2-redirect.html", // AdministrationService redirect uri
$"{saasServiceRootUrl}/swagger/oauth2-redirect.html", // SaasService redirect uri
$"{productServiceRootUrl}/swagger/oauth2-redirect.html", // ProductService redirect uri
}
);
}
}
Creating Applications
While public-web and administration service clients are distinct, all the other back-office clients are created by default. Administration service is used to make requests to identity service to get user permission data. See administration service for more.
private async Task CreateClientsAsync()
{
var commonScopes = new List<string>
{
OpenIddictConstants.Permissions.Scopes.Address,
OpenIddictConstants.Permissions.Scopes.Email,
OpenIddictConstants.Permissions.Scopes.Phone,
OpenIddictConstants.Permissions.Scopes.Profile,
OpenIddictConstants.Permissions.Scopes.Roles
};
//Web Client
var webClientRootUrl = _configuration["OpenIddict:Applications:MyProjectName_Web:RootUrl"].EnsureEndsWith('/');
await CreateApplicationAsync(
name: "MyProjectName_Web",
type: OpenIddictConstants.ClientTypes.Confidential,
consentType: OpenIddictConstants.ConsentTypes.Implicit,
displayName: "Web Client",
secret: "1q2w3e*",
grantTypes: new List<string> //Hybrid flow
{
OpenIddictConstants.GrantTypes.AuthorizationCode,
OpenIddictConstants.GrantTypes.Implicit
},
scopes: commonScopes.Union(new[] {"AccountService", "IdentityService", "AdministrationService", "SaasService", "ProductService"}).ToList(),
redirectUris: new List<string> { $"{webClientRootUrl}signin-oidc" },
postLogoutRedirectUris: new List<string>() { $"{webClientRootUrl}signout-callback-oidc" }
);
//Blazor Client
var blazorClientRootUrl = _configuration["OpenIddict:Applications:MyProjectName_Blazor:RootUrl"].EnsureEndsWith('/');
await CreateApplicationAsync(
name: "MyProjectName_Blazor",
type: OpenIddictConstants.ClientTypes.Public,
consentType: OpenIddictConstants.ConsentTypes.Implicit,
displayName: "Blazor Client",
secret: null,
grantTypes: new List<string>
{
OpenIddictConstants.GrantTypes.AuthorizationCode
},
scopes: commonScopes.Union(new[] {"AccountService", "IdentityService", "AdministrationService", "SaasService", "ProductService"}).ToList(),
redirectUris: new List<string> { $"{blazorClientRootUrl}authentication/login-callback" },
postLogoutRedirectUris: new List<string> { $"{blazorClientRootUrl}authentication/logout-callback" }
);
//Blazor Server Client
var blazorServerClientRootUrl = _configuration["OpenIddict:Applications:MyProjectName_BlazorServer:RootUrl"].EnsureEndsWith('/');
await CreateApplicationAsync(
name: "MyProjectName_BlazorServer",
type: OpenIddictConstants.ClientTypes.Confidential,
consentType: OpenIddictConstants.ConsentTypes.Implicit,
displayName: "Blazor Server Client",
secret: "1q2w3e*",
grantTypes: new List<string> //Hybrid flow
{
OpenIddictConstants.GrantTypes.AuthorizationCode,
OpenIddictConstants.GrantTypes.Implicit
},
scopes: commonScopes.Union(new[] {"AccountService", "IdentityService", "AdministrationService", "SaasService", "ProductService" }).ToList(),
redirectUris: new List<string> { $"{blazorServerClientRootUrl}signin-oidc" },
postLogoutRedirectUris: new List<string> { $"{blazorServerClientRootUrl}signout-callback-oidc" }
);
//Public Web Client
var publicWebClientRootUrl = _configuration["OpenIddict:Applications:MyProjectName_PublicWeb:RootUrl"].EnsureEndsWith('/');
await CreateApplicationAsync(
name: "MyProjectName_PublicWeb",
type: OpenIddictConstants.ClientTypes.Confidential,
consentType: OpenIddictConstants.ConsentTypes.Implicit,
displayName: "Public Web Client",
secret: "1q2w3e*",
grantTypes: new List<string> //Hybrid flow
{
OpenIddictConstants.GrantTypes.AuthorizationCode,
OpenIddictConstants.GrantTypes.Implicit
},
scopes: commonScopes.Union(new[] { "AccountService", "AdministrationService", "ProductService" }).ToList(),
redirectUris: new List<string> { $"{publicWebClientRootUrl}signin-oidc" },
postLogoutRedirectUris: new List<string> { $"{publicWebClientRootUrl}signout-callback-oidc" }
);
//Angular Client
var angularClientRootUrl = _configuration["OpenIddict:Applications:MyProjectName_Angular:RootUrl"].TrimEnd('/');
await CreateApplicationAsync(
name: "MyProjectName_Angular",
type: OpenIddictConstants.ClientTypes.Public,
consentType: OpenIddictConstants.ConsentTypes.Implicit,
displayName: "Angular Client",
secret: null,
grantTypes: new List<string>
{
OpenIddictConstants.GrantTypes.AuthorizationCode,
OpenIddictConstants.GrantTypes.RefreshToken,
OpenIddictConstants.GrantTypes.Password,
"LinkLogin",
"Impersonation"
},
scopes: commonScopes.Union(new[] {"AccountService", "IdentityService", "AdministrationService", "SaasService", "ProductService" }).ToList(),
redirectUris: new List<string> { $"{angularClientRootUrl}" },
postLogoutRedirectUris: new List<string> { $"{angularClientRootUrl}" }
);
//Administration Service Client
await CreateApplicationAsync(
name: "MyProjectName_AdministrationService",
type: OpenIddictConstants.ClientTypes.Confidential,
consentType: OpenIddictConstants.ConsentTypes.Implicit,
displayName: "Administration Service Client",
secret: "1q2w3e*",
grantTypes: new List<string>
{
OpenIddictConstants.GrantTypes.ClientCredentials
},
scopes: commonScopes.Union(new[] { "IdentityService" }).ToList(),
permissions: new List<string> { IdentityPermissions.Users.Default }
);
}
If you have created an angular back-office application in your microservice template, you are free to delete blazor server, blazor and web clients.
Auto Migration Data Seeding
IdentityServiceDatabaseMigrationEventHandler is used for seeding language management and identity data.
Data seeding occurs when the database is migrated:
public async Task HandleEventAsync(ApplyDatabaseMigrationsEto eventData)
{
...
await SeedDataAsync(
tenantId: eventData.TenantId,
adminEmail: IdentityServiceDbProperties.DefaultAdminEmailAddress,
adminPassword: IdentityServiceDbProperties.DefaultAdminPassword
);
...
}
Or when a tenant is created:
public async Task HandleEventAsync(TenantCreatedEto eventData)
{
...
await SeedDataAsync(
tenantId: eventData.Id,
adminEmail: eventData.Properties.GetOrDefault(IdentityDataSeedContributor.AdminEmailPropertyName) ?? IdentityServiceDbProperties.DefaultAdminEmailAddress,
adminPassword: eventData.Properties.GetOrDefault(IdentityDataSeedContributor.AdminPasswordPropertyName) ?? IdentityServiceDbProperties.DefaultAdminPassword
);
...
}
Or when a tenants connection string is updated:
public async Task HandleEventAsync(TenantConnectionStringUpdatedEto eventData)
{
...
await SeedDataAsync(
tenantId: eventData.Id,
adminEmail: IdentityServiceDbProperties.DefaultAdminEmailAddress,
adminPassword: IdentityServiceDbProperties.DefaultAdminPassword
);
...
}
Changing the connection string will cause the creation of a new database. This database will be empty if data from the old database is not moved to the new database. It is left for the developer's choice.
DbMigrator Data Seeding
Host data is seeded in MigrateHostAsync method:
private async Task MigrateHostAsync(CancellationToken cancellationToken)
{
_logger.LogInformation("Migrating Host side...");
await MigrateAllDatabasesAsync(null, cancellationToken);
await SeedDataAsync();
}
IdentityServiceDataSeeder is used for seeding the required OpenIddictDataSeeder and seeding data runs after migrating all the databases:
private async Task SeedDataAsync()
{
await _dataSeeder.SeedAsync(
new DataSeedContext(_currentTenant.Id)
.WithProperty(IdentityDataSeedContributor.AdminEmailPropertyName,
IdentityServiceDbProperties.DefaultAdminEmailAddress)
.WithProperty(IdentityDataSeedContributor.AdminPasswordPropertyName,
IdentityServiceDbProperties.DefaultAdminPassword)
);
}
Tenant data is seeded after host data is migrated in the MigrateTenantsAsync method after tenant database migration is completed:
private async Task MigrateTenantsAsync(CancellationToken cancellationToken)
{
...
using (_currentTenant.Change(tenant.Id))
{
...
//Seed data
_logger.LogInformation($"Seeding tenant data: {tenant.Name} ({tenant.Id})");
await SeedDataAsync();
}
...
}
If you decide to use both DbMigrator and Auto Migration approaches, you need to keep both
IdentityServerDataSeederfiles located under IdentityService/DbMigrations and DbMigrator projects synchronized.
AdministrationService Data Seeding
AdministrationService uses two different mapped database configurations; AdministrationService and SaasService which are located under appsettings.json file. AdministrationService seeds the initial admin permission data.
Auto Migration Data Seeding
AdministrationServiceDatabaseMigrationEventHandler is used for seeding permissions:
private async Task SeedDataAsync(Guid? tenantId)
{
using (CurrentTenant.Change(tenantId))
{
using (var uow = UnitOfWorkManager.Begin(requiresNew: true, isTransactional: true))
{
var multiTenancySide = tenantId == null
? MultiTenancySides.Host
: MultiTenancySides.Tenant;
var permissionNames = _permissionDefinitionManager
.GetPermissions()
.Where(p => p.MultiTenancySide.HasFlag(multiTenancySide))
.Where(p => !p.Providers.Any() || p.Providers.Contains(RolePermissionValueProvider.ProviderName))
.Select(p => p.Name)
.ToArray();
await _permissionDataSeeder.SeedAsync(
RolePermissionValueProvider.ProviderName,
"admin",
permissionNames,
tenantId
);
await uow.CompleteAsync();
}
}
}
Data seeding occurs when database is migrated:
public async Task HandleEventAsync(ApplyDatabaseMigrationsEto eventData)
{
...
await SeedDataAsync(eventData.TenantId);
...
}
Or when a tenant is created:
public async Task HandleEventAsync(TenantCreatedEto eventData)
{
...
await SeedDataAsync(eventData.Id);
...
}
Or when a tenants connection string is updated:
public async Task HandleEventAsync(TenantConnectionStringUpdatedEto eventData)
{
...
await MigrateDatabaseSchemaAsync(eventData.Id);
await SeedDataAsync(eventData.Id);
...
}
DbMigrator Data Seeding
IDataSeeder is used for seeding the required data.
SaasService Data Seeding
SaasService uses two different mapped database configurations; SaasService and AdministrationService which are located under appsettings.json file. SaasService does not seed any initial data. If an initial Saas data is required to be seeded, create a SaasDataSeedContibutor.
SaasService database is only available for the host side.
Auto Migration Data Seeding
SaasServiceDatabaseMigrationEventHandler is used for seeding initial Saas data by calling SeedAsync method of the newly created SaasDataSeedContibutor after migrating the database schema.
public async Task HandleEventAsync(ApplyDatabaseMigrationsEto eventData)
{
...
await MigrateDatabaseSchemaAsync(null);
// Seed data here
...
}
SaasServiceDatabaseMigrationEventHandler only handles
ApplyDatabaseMigrationsEtoby default.
DbMigrator Data Seeding
IDataSeeder is used for seeding the required data and Data seed contributors are automatically discovered by the ABP Framework and executed as a part of the data seed process.
ProductService Data Seeding
ProductService uses three different mapped database configurations; ProductService, AdministrationService, and SaasService which are located under appsettings.json file. ProductService does not seed any initial data. If an initial product data is required to be seeded, create a ProductDataSeedContibutor.
Auto Migration Data Seeding
ProductServiceDatabaseMigrationEventHandler is used for seeding initial product data by calling SeedAsync method of the newly created ProductDataSeedContibutor after migrating the database schema.
public async Task HandleEventAsync(ApplyDatabaseMigrationsEto eventData)
{
...
var schemaMigrated = await MigrateDatabaseSchemaAsync(eventData.TenantId);
// Seed data here
...
}
If the product data needs to be seeded when a tenant is created:
public async Task HandleEventAsync(TenantCreatedEto eventData)
{
...
await MigrateDatabaseSchemaAsync(eventData.Id);
// Seed data here
...
}
Or when a tenants connection string is updated:
public async Task HandleEventAsync(TenantConnectionStringUpdatedEto eventData)
{
...
await MigrateDatabaseSchemaAsync(eventData.Id);
// Seed data here
...
}
DbMigrator Data Seeding
Generic IDataSeeder is used to seed the required data and Data seed contributors are automatically discovered by the ABP Framework and executed as a part of the data seed process.


